Autocomplete in Python
––– views
By Elijah (Eli) Wilson
User experience (UX) has become a large industry and many companies are now looking specifically for UX engineers. Autocomplete has been one piece of UX that seems to be everywhere now; from our phones to the web browser. It doesn’t seem like a technology that is necessarily difficult or complex to implement. From many aspects I think that is true, however, if you’re trying to optimize performance or do fuzzy matching then it can become very slow very quickly. Let’s say for example we’re building a feature that is similar to the DuckDuckGo search bar. As you type words, it gives you suggestions based on what you’ve typed so far.
There are roughly half a million words in the English language. How do you show these suggestions to a user? Secondly, you’ll notice as you’re typing you’re not shown just any random words. DuckDuckGo has a way of weighing each suggestion for the next word. In practice, there would likely be some dynamic weighting based on sentence structure, but let’s assume for the purpose of this post that each word has a simple weighting based on how common it is.
The Trie Data Structure
When thinking about ways to solve this problem, you may think of a couple of things. We could sort the list of words, and then iterate through all the words starting with the first character. Of course, that would be very slow, O(n) if n is the number of words in our dictionary. We can do better than that! What about a database? Could we store each word in a database and do a query like so?
We could do that, however, then we’ll need to properly index the database and maintain it. What if I told you we can do this in less than 100 lines of Python? And what if I told you we can store every word in with less than 500MB of memory? I’m here to tell you, it’s possible! Let’s go back to our original example of sorting our list of words and iterating through all the words starting with the first character of our word. How would we know where to start? Well, if we used a dictionary we could store the first letter of each word (26 lowercase characters, excluding punctuation) as the key and then each word as a list under it. That’s a good start! We can still do better though! What if we then used a similar structure for each character in each of those words? We’d get a structure similar to this:
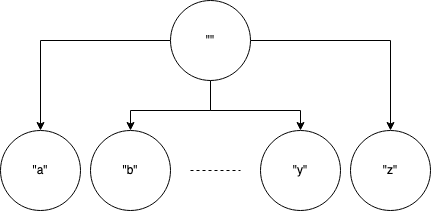
This data structure is called a “Trie”. It’s very similar to a tree where each node stores a single character. At most, each node will store 26 children keys. Seems straightforward enough right? Let’s first look at how we can add words to our Trie data structure then look into how to query it.
A Trie in Python
Python 3 introduced the slots class level attribute which does not use an internal dict for storing attributes. This reduces the memory needed for each class as well as makes attribute lookups much faster. When writing this article the memory used without slots was almost 900MB. After using slots it decreased to just over 500MB. Our TrieNode class will just have a value, end_of_word, children, and weight attributes. To add a new word, we’ll look at the word character by character. For the word “foo”, we could think of our path as root -> “f” -> “o” -> “o”. Where each “->” denotes child access. As we recurse through each character node, we take off one character after each level. Finally, when we are at the last character, we mark it as the end of the word.
Now that we have a way to populate our Trie, we need to get a word list. The dwyl/english-words repository is great and has a list of almost 500,000 English words. Each word is separated by a new line so we can simply read all the lines in the file and load them into our Trie. I also opted to use a library called tqdm to show a progress bar as these are loaded since it does take a minute or so.
How do we actually query our Trie? This is the most complicated part in my opinion. We need to keep two lists; one that is of the characters we haven’t seen yet and the characters we have seen so far. Let’s think of a simple word list and walk through some pseudocode. If our word list contains [“foo”, “food”, “fun”, “funky”, “funny”] and our query is “fo”, this is what should happen:
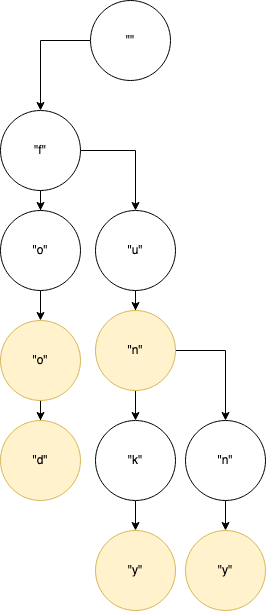
First, the characters we’ve seen so far are none, and we still have “f” and “o” to traverse. If there are still characters left in our word, then we should look in the current node’s children for the first character. In our case, we’d ask the root node for its “f” child. Now that we have the “f” node, we pass in our new word part which is just “o” and our path is now “f”. In the “f” node, we look for the “o” child. With that node, we then pass the word part we haven’t seen yet which is just an empty string, and our path will be “fo”. Since we don’t have any characters left in our query word, we can go through all of the “o” node’s children and yield all their combinations. In our simple word list that will be “foo” and “food”. If at any point in this process we reach a node that has end_of_word set to True then we should yield our path so far plus our current node value.
Let’s try querying!
Query the Trie over HTTP
We can now query our Trie and that’s pretty awesome. The last part will be to expose this as an API. I’ve chosen to use FastAPI but the same idea can be applied to Django, Flask, or whatever other frameworks you want to use. Earlier in the post, I said it would be useful for each word to have a weighting, when we imported our words we just gave them an equal weighting of 1, but we can still use that value. After we get all the suggested words, we can sort them in descending order based on that weight and secondarily sort by the actual word. Lastly, in our API output, I decided to add the time it takes to call our API along with the suggested words. To use the endpoint we can use a library called HTTPie or you can use cURL if you like.
Look at that! We can now query our Trie via an HTTP API and are well on our way to building a fully functional DuckDuckGo autocomplete feature. The trick, of course, is in the weighting of the words. In addition, it probably would make sense for our suggestions to be grammatically correct too. If someone is typing “something co” it likely wouldn’t make sense to suggest “something cod”, whereas “something cool” might make more sense.
Appendix I
You may be wondering how I calculated the size of our Trie in memory. It’s not a perfect science, but I think it’s close. I found this article from Shippo but it didn’t include slots. Luckily there is a pysize repo that takes them into consideration. I also think it may be interesting to use a Python 3.7 data class instead of slots and compare the memory size.
Here's the full code: